
Reinforcement learning streamlined.
Easier and faster reinforcement learning with RLOps.
Visit our website. View documentation.
Join the Discord Server for questions, help and collaboration.
Train super-fast for free on Arena, the RLOps platform from AgileRL.
🚀 Train super-fast for free on Arena, the RLOps platform from AgileRL 🚀
AgileRL is a Deep Reinforcement Learning library focused on improving development by introducing RLOps - MLOps for reinforcement learning.
This library is initially focused on reducing the time taken for training models and hyperparameter optimization (HPO) by pioneering evolutionary HPO techniques for reinforcement learning. Evolutionary HPO has been shown to drastically reduce overall training times by automatically converging on optimal hyperparameters, without requiring numerous training runs.
We are constantly adding more algorithms and features. AgileRL already includes state-of-the-art evolvable LLM fine-tuning, on-policy, off-policy, offline, multi-agent and contextual multi-armed bandit reinforcement learning algorithms with distributed training.

AgileRL offers 10x faster hyperparameter optimization than SOTA.¶
Benchmarks
LLM Fine-tuning
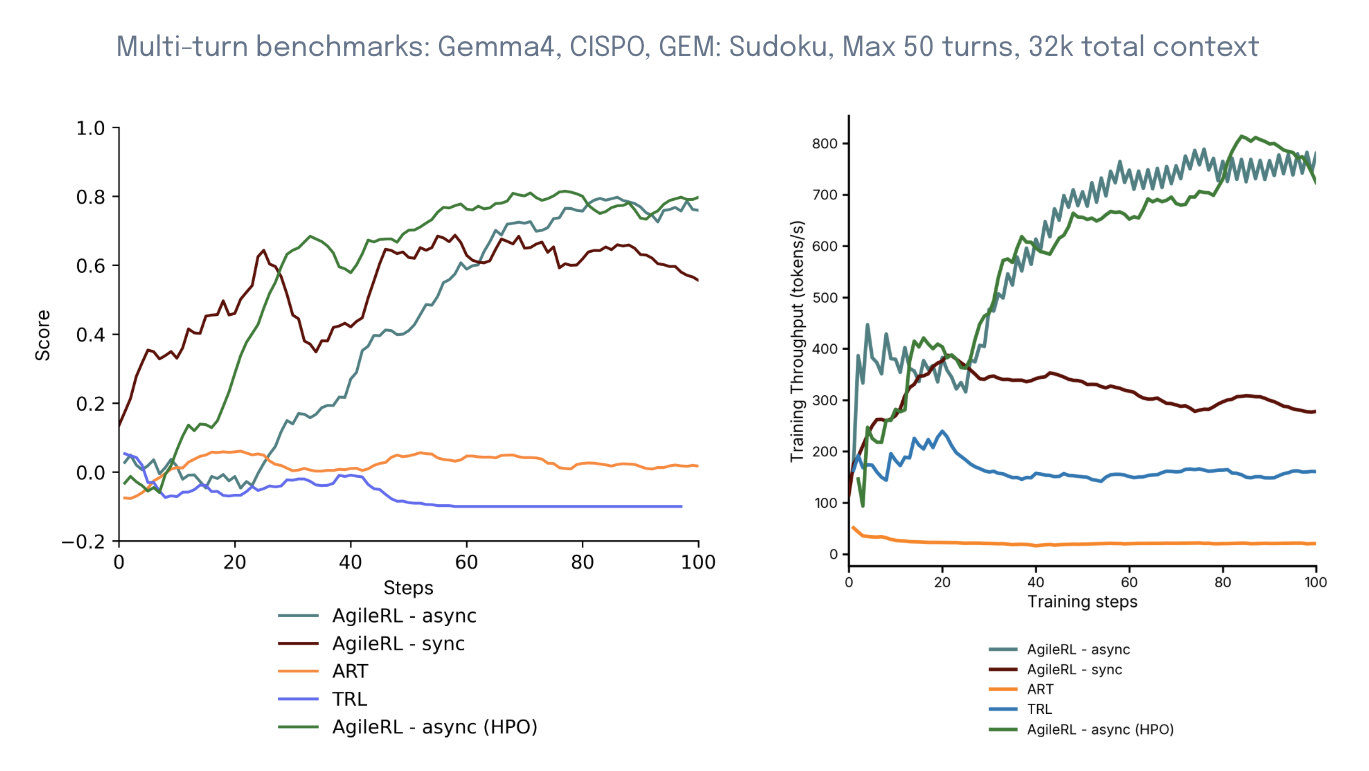
AgileRL’s multi-turn LLM training enables state-of-the-art performance on long-horizon tasks with small models. In the following example, AgileRL’s CISPO was benchmarked against ART and TRL on the GEM Sudoku Hard task. This is a difficult multi-turn problem, which requires a context length of 32k tokens and up to 50 turns per rollout. The sync AgileRL run is a single agent using the AgileRL framework. The async and HPO runs were performed on Arena, AgileRL’s RLOps platform. All runs used the same starting hyperparameters. AgileRL runs were run on A100 40GB nodes, whereas ART and TRL required A100 80GB nodes due to a lack of optimizations. AgileRL runs significantly outperformed those using the ART and TRL frameworks.
Classic RL
Reinforcement learning algorithms and libraries are usually benchmarked once the optimal hyperparameters for training are known, but it often takes hundreds or thousands of experiments to discover these. This is unrealistic and does not reflect the true, total time taken for training. What if we could remove the need to conduct all these prior experiments?
In the charts below, a single AgileRL run, which automatically tunes hyperparameters, is benchmarked against Optuna’s multiple training runs traditionally required for hyperparameter optimization, demonstrating the real time savings possible. Global steps is the sum of every step taken by any agent in the environment, including across an entire population.

AgileRL offers an order of magnitude speed up in hyperparameter optimization vs popular reinforcement learning training frameworks combined with Optuna. Remove the need for multiple training runs and save yourself hours.¶
AgileRL also supports multi-agent reinforcement learning using the Petting Zoo-style (parallel API). The charts below highlight the performance of our MADDPG and MATD3 algorithms with evolutionary hyper-parameter optimisation (HPO), benchmarked against epymarl’s MADDPG algorithm with grid-search HPO for the simple speaker listener and simple spread environments.

Citing AgileRL
If you use AgileRL in your work, please cite the repository:
@software{Ustaran-Anderegg_AgileRL,
author = {Ustaran-Anderegg, Nicholas and Pratt, Michael and Sabal-Bermudez, Jaime},
license = {Apache-2.0},
title = {{AgileRL}},
url = {https://github.com/AgileRL/AgileRL}
}
Contents
Introduction
Arena
Training
- Evolutionary Hyperparameter Optimization
- Off-Policy Training
- On-Policy Training
- Partially Observable Markov Decision Processes (POMDPs)
- Offline Training
- Multi-Agent Training
- LLM Fine-Tuning
- Contextual Multi-Armed Bandits
- Distributed Training
- Trainers
- Evolvable Neural Networks
- Creating Custom Algorithms
- Debugging Reinforcement Learning
Observability
Tutorials
API
Development