PenDigits with NeuralTS¶
In this tutorial, we will be training a NeuralTS agent to solve the PenDigits dataset, converted into a bandit environment. We will also use evolutionary hyperparameter optimization on a population of agents.
To complete the PenDigits environment, the agent must learn to select the best arm, or action, to take in a given context, or state.
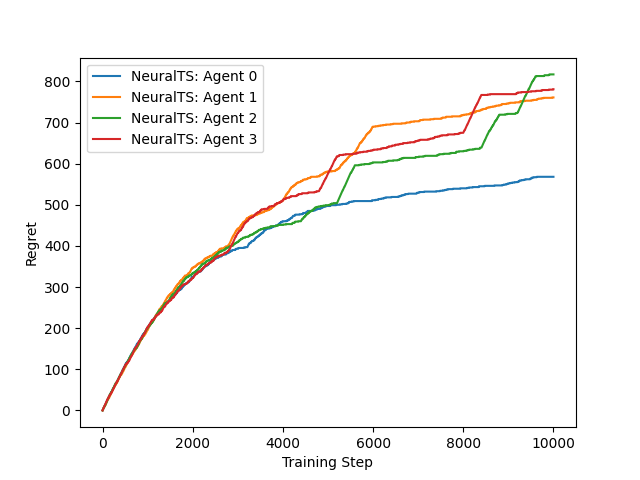
Figure 1: Cumulative regret from training on the PenDigits dataset¶ |
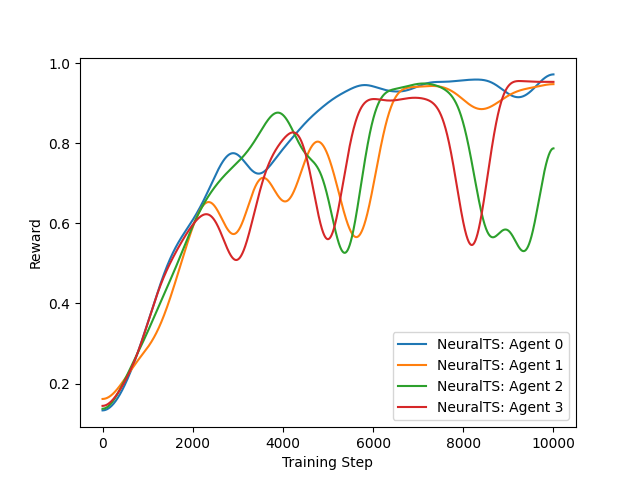
Figure 2: Reward from training on the PenDigits dataset¶ |
NeuralTS (Neural Contextual Bandits with Thompson Sampling) adapts deep neural networks for both exploration and exploitation by using a posterior distribution of the reward with a neural network approximator as its mean, and neural tangent features as its variance.
For this tutorial, we will use the labelled PenDigits dataset from the UCI Machine Learning Repository.
These datasets can easily be imported and used for training with the Python package ucimlrepo, and to choose from the hundreds of
available datasets it is as simple as changing the id parameter used by fetch_uci_repo.
We can convert these labelled datasets into a bandit learning environment easily by using the agilerl.wrappers.learning.BanditEnv class.
"""This tutorial shows how to train an NeuralTS agent on the PenDigits dataset with evolutionary HPO.
Authors: Nick (https://github.com/nicku-a)
"""
import matplotlib.pyplot as plt
import numpy as np
import torch
from gymnasium import spaces
from tensordict import TensorDict
from tutorials.utils import require_package
with require_package():
from scipy.ndimage import gaussian_filter1d
from ucimlrepo import fetch_ucirepo
from agilerl.algorithms import NeuralTS
from agilerl.algorithms.core.registry import HyperparameterConfig, RLParameter
from agilerl.components.replay_buffer import ReplayBuffer
from agilerl.hpo.mutation import Mutations
from agilerl.hpo.tournament import TournamentSelection
from agilerl.utils.utils import default_progress_bar
from agilerl.wrappers.learning import BanditEnv
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Network configuration
net_config = {
"latent_dim": 64,
"encoder_config": {"hidden_size": [64]},
"head_config": {"hidden_size": [64]},
}
# Algorithm hyperparameters
init_hp = {
"batch_size": 64,
"lr": 0.001,
"gamma": 1.0,
"lamb": 1.0,
"reg": 0.0625,
"learn_step": 2,
}
population_size = 4
# Fetch data https://archive.ics.uci.edu/
pendigits = fetch_ucirepo(id=81)
features = pendigits.data.features
targets = pendigits.data.targets
env = BanditEnv(features, targets) # Create environment
context_dim = env.context_dim
action_dim = env.arms
# Mutation config for RL hyperparameters
hp_config = HyperparameterConfig(
lr=RLParameter(min=6.25e-5, max=1e-2),
batch_size=RLParameter(min=8, max=512, dtype=int),
learn_step=RLParameter(
min=1,
max=10,
dtype=int,
grow_factor=1.5,
shrink_factor=0.75,
),
)
# Define observation and action spaces from dataset
observation_space = spaces.Box(
low=features.values.min(),
high=features.values.max(),
shape=context_dim,
)
action_space = spaces.Discrete(action_dim)
# Create population of agents
pop = NeuralTS.population(
size=population_size,
observation_space=observation_space,
action_space=action_space,
net_config=net_config,
hp_config=hp_config,
device=device,
**init_hp,
)
memory = ReplayBuffer(
max_size=10000, # Max replay buffer size
device=device,
)
tournament = TournamentSelection(
tournament_size=2, # Tournament selection size
elitism=True, # Elitism in tournament selection
population_size=population_size, # Population size
)
mutations = Mutations(
no_mutation=0.4, # No mutation
architecture=0.2, # Architecture mutation
new_layer_prob=0.2, # New layer mutation
parameters=0.2, # Network parameters mutation
activation=0.2, # Activation layer mutation
rl_hp=0.2, # Learning HP mutation
mutation_sd=0.1, # Mutation strength
mutate_elite=False, # Mutate best agent in population # Network architecture
rand_seed=1, # Random seed
device=device,
)
max_steps = 2500 # Max steps per episode
episode_steps = 500 # Steps in episode
evo_steps = 1000 # Evolution frequency
eval_steps = 500 # Evaluation steps per episode
eval_loop = 1 # Number of evaluation episodes
evo_count = 0
regret = [[0] for _ in pop]
score = [[0] for _ in pop]
total_steps = 0
# TRAINING LOOP
print("Training...")
pbar = default_progress_bar(max_steps)
while np.less([agent.steps for agent in pop], max_steps).all():
for i, agent in enumerate(pop): # Loop through population
context = env.reset() # Reset environment at start of episode
for _ in range(episode_steps):
# Get next action from agent
action = agent.get_action(context)
next_context, reward = env.step(action) # Act in environment
transition = TensorDict(
{
"obs": context[action],
"reward": reward,
},
).float()
transition = transition.unsqueeze(0)
transition.batch_size = [1]
# Save experience to replay buffer
memory.add(transition)
# Learn according to learning frequency
if len(memory) >= agent.batch_size:
for _ in range(agent.learn_step):
# Sample replay buffer
# Learn according to agent's RL algorithm
experiences = memory.sample(agent.batch_size)
agent.learn(experiences)
context = next_context
score[i].append(reward)
regret[i].append(regret[i][-1] + 1 - reward)
total_steps += episode_steps
agent.steps += episode_steps
pbar.update(episode_steps)
fitnesses = [
agent.test(
env,
max_steps=eval_steps,
loop=eval_loop,
)
for agent in pop
]
pbar.write(
f"--- Global steps {total_steps} ---\n"
f"Steps {[agent.steps for agent in pop]}\n"
f"Regret: {[regret[i][-1] for i in range(len(pop))]}\n"
f"Fitnesses: {[f'{fitness:.2f}' for fitness in fitnesses]}"
f"Mutations: {[agent.mut for agent in pop]}",
)
if pop[0].steps // evo_steps > evo_count:
# Tournament selection and population mutation
elite, pop = tournament.select(pop)
pop = mutations.mutation(pop)
evo_count += 1
# Plot the results
plt.figure()
for i, agent_regret in enumerate(regret):
plt.plot(
np.linspace(0, total_steps, len(agent_regret)),
agent_regret,
label=f"NeuralTS: Agent {i}",
)
plt.xlabel("Training Step")
plt.ylabel("Regret")
plt.legend()
plt.savefig("NeuralTS-PenDigits-regret.png")
plt.figure()
for i, agent_score in enumerate(score):
smoothed_score = gaussian_filter1d(agent_score, sigma=80)
plt.plot(
np.linspace(0, total_steps, len(smoothed_score)),
smoothed_score,
label=f"NeuralTS: Agent {i}",
)
plt.xlabel("Training Step")
plt.ylabel("Reward")
plt.legend()
plt.savefig("NeuralTS-PenDigits-reward.png")