Evolvable Neural Networks¶
Other than the hyperparemeters pertaining to the specific algorithm you’re using to optimize your agent, a large source of variance in the performance of your agent is the choice network architecture. Tuning the architecture of your network is usually a very time-consuming and tedious task, requiring multiple training runs that can take days or even weeks to execute. AgileRL allows you to automatically tune the architecture of your network in a single training run through evolutionary hyperparameter optimization.
Neural Network Building Blocks¶
We address the above issue by introducing a framework for performing architecture mutations through the EvolvableModule
abstraction (which is a wrapper around torch.nn.Module). It allows us to seamlessly track and apply architecture mutations for networks with nested evolvable modules.
This is particularly useful for RL algorithms, where we define default configurations suitable for a variety of problems (i.e. combinations of observation and action spaces),
which require very different network architectures.

Structure of an EvolvableModule showing the relationship with torch.nn.Module and mutation capabilities¶
Examples of the basic modules included in AgileRL are:
EvolvableMLP: Multi-layer perceptron (MLP) network that maps vector observations to a desired number of outputs, including mutation methods that allow for the random addition or removal of layers and nodes.EvolvableCNN: Convolutional neural network (CNN) that maps image observations to a desired number of outputs, including mutation methods that allow for the random addition or removal of convolutional layers and neurons, as well as changing the kernel sizes.EvolvableMultiInput: Network that maps dictionary or tuple observations to a desired number of outputs. This module includes nestedEvolvableModule’s to process each element of the dictionary or tuple observation separately into a latent space, which are then concatenated and processed by a final dense layer to form a number of outputs. Includes the mutation methods of all nestedEvolvableModule’s.
Below is an example of the simplest evolvable module included in AgileRL, the EvolvableMLP.
Example: EvolvableMLP
EvolvableMLP
from typing import Any
import torch
from agilerl.modules.base import EvolvableModule, MutationType, mutation
from agilerl.typing import ArrayOrTensor
from agilerl.utils.evolvable_networks import create_mlp
class EvolvableMLP(EvolvableModule):
"""The Evolvable Multi-layer Perceptron class. Consists of a sequence of fully connected linear layers
with an optional activation function between each layer. Supports using layer normalization, using noisy
linear layers, and vanishing the values of the weights in the output layer. Allows for the following types
of architecture mutations during training:
* Adding or removing hidden layers
* Adding or removing nodes from hidden layers
* Changing the activation function between layers (e.g. ReLU to GELU)
* Changing the activation function for the output layer (e.g. ReLU to GELU)
:param num_inputs: Input layer dimension
:type num_inputs: int
:param num_outputs: Output layer dimension
:type num_outputs: int
:param hidden_size: Hidden layer(s) size
:type hidden_size: list[int]
:param activation: Activation layer, defaults to 'ReLU'
:type activation: str, optional
:param output_activation: Output activation layer, defaults to None
:type output_activation: str, optional
:param min_hidden_layers: Minimum number of hidden layers the network will shrink down to, defaults to 1
:type min_hidden_layers: int, optional
:param max_hidden_layers: Maximum number of hidden layers the network will expand to, defaults to 3
:type max_hidden_layers: int, optional
:param min_mlp_nodes: Minimum number of nodes a layer can have within the network, defaults to 64
:type min_mlp_nodes: int, optional
:param max_mlp_nodes: Maximum number of nodes a layer can have within the network, defaults to 500
:type max_mlp_nodes: int, optional
:param layer_norm: Normalization between layers, defaults to True
:type layer_norm: bool, optional
:param output_layernorm: Normalization for the output layer, defaults to False
:type output_layernorm: bool, optional
:param output_vanish: Vanish output by multiplying by 0.1, defaults to True
:type output_vanish: bool, optional
:param init_layers: Initialise network layers, defaults to True
:type init_layers: bool, optional
:param noise_std: Noise standard deviation, defaults to 0.5
:type noise_std: float, optional
:param noisy: Add noise to network, defaults to False
:type noisy: bool, optional
:param new_gelu: Use new GELU activation function, defaults to False
:type new_gelu: bool, optional
:param device: Device for accelerated computing, 'cpu' or 'cuda', defaults to 'cpu'
:type device: str, optional
:param name: Name of the network, defaults to 'mlp'
:type name: str, optional
:param random_seed: Random seed to use for the network. Defaults to None.
:type random_seed: int | None
"""
def __init__(
self,
num_inputs: int,
num_outputs: int,
hidden_size: list[int],
activation: str = "ReLU",
output_activation: str | None = None,
min_hidden_layers: int = 1,
max_hidden_layers: int = 3,
min_mlp_nodes: int = 32,
max_mlp_nodes: int = 500,
layer_norm: bool = True,
output_layernorm: bool = False,
output_vanish: bool = True,
init_layers: bool = True,
noisy: bool = False,
noise_std: float = 0.5,
new_gelu: bool = False,
device: str = "cpu",
name: str = "mlp",
random_seed: int | None = None,
) -> None:
super().__init__(device, random_seed)
assert num_inputs > 0, (
"'num_inputs' cannot be less than or equal to zero, please enter a valid integer."
)
assert num_outputs > 0, (
"'num_outputs' cannot be less than or equal to zero, please enter a valid integer."
)
for num in hidden_size:
assert num > 0, (
"'hidden_size' cannot contain zero, please enter a valid integer."
)
assert len(hidden_size) != 0, "MLP must contain at least one hidden layer."
assert min_hidden_layers < max_hidden_layers, (
"'min_hidden_layers' must be less than 'max_hidden_layers."
)
assert min_mlp_nodes < max_mlp_nodes, (
"'min_mlp_nodes' must be less than 'max_mlp_nodes."
)
self.name = name
self.num_inputs = num_inputs
self.num_outputs = num_outputs
self._activation = activation
self.new_gelu = new_gelu
self.output_activation = output_activation
self.min_hidden_layers = min_hidden_layers
self.max_hidden_layers = max_hidden_layers
self.min_mlp_nodes = min_mlp_nodes
self.max_mlp_nodes = max_mlp_nodes
self.layer_norm = layer_norm
self.output_vanish = output_vanish
self.output_layernorm = output_layernorm
self.init_layers = init_layers
self.hidden_size = hidden_size
self.noisy = noisy
self.noise_std = noise_std
self.model = create_mlp(
input_size=self.num_inputs,
output_size=self.num_outputs,
hidden_size=self.hidden_size,
output_vanish=self.output_vanish,
output_activation=self.output_activation,
noisy=self.noisy,
init_layers=self.init_layers,
layer_norm=self.layer_norm,
output_layernorm=self.output_layernorm,
activation=self.activation,
noise_std=self.noise_std,
device=self.device,
new_gelu=self.new_gelu,
name=self.name,
)
@property
def net_config(self) -> dict[str, Any]:
"""Return model configuration in dictionary.
:return: Model configuration
:rtype: dict[str, Any]
"""
net_config = self.init_dict.copy()
for attr in ["num_inputs", "num_outputs", "device", "name"]:
if attr in net_config:
net_config.pop(attr)
return net_config
@property
def activation(self) -> str:
"""Return activation function.
:return: Activation function
:rtype: str
"""
return self._activation
@activation.setter
def activation(self, activation: str) -> None:
"""Set activation function.
:param activation: Activation function to use.
:type activation: str
"""
self._activation = activation
def init_weights_gaussian(
self,
std_coeff: float = 4,
output_coeff: float = 4,
) -> None:
"""Initialise weights of neural network using Gaussian distribution.
:param std_coeff: Standard deviation coefficient, defaults to 4
:type std_coeff: float, optional
:param output_coeff: Output layer standard deviation coefficient, defaults to 4
:type output_coeff: float, optional
"""
EvolvableModule.init_weights_gaussian(self.model, std_coeff=std_coeff)
# Output layer is initialised with std_coeff=2
output_layer = self.get_output_dense()
EvolvableModule.init_weights_gaussian(output_layer, std_coeff=output_coeff)
def forward(self, x: ArrayOrTensor) -> torch.Tensor:
"""Return output of neural network.
:param x: Neural network input
:type x: torch.Tensor or np.ndarray
:return: Neural network output
:rtype: torch.Tensor
"""
if not isinstance(x, torch.Tensor):
x = torch.tensor(x, dtype=torch.float32, device=self.device)
if len(x.shape) == 1:
x = x.unsqueeze(0)
return self.model(x)
def get_output_dense(self) -> torch.nn.Module:
"""Return output layer of neural network.
:return: Output layer of neural network
:rtype: torch.nn.Module
"""
return getattr(self.model, f"{self.name}_linear_layer_output")
def change_activation(self, activation: str, output: bool = False) -> None:
"""Set the activation function for the network.
:param activation: Activation function to use.
:type activation: str
:param output: Flag indicating whether to set the output activation function, defaults to False
:type output: bool, optional
"""
if output:
self.output_activation = activation
self.activation = activation
self.recreate_network()
@mutation(MutationType.LAYER)
def add_layer(self) -> dict[str, int] | None:
"""Add a hidden layer to neural network. Falls back on ``add_node()`` if ``max_hidden_layers`` reached.
:return: Dictionary containing the hidden layer and number of new nodes.
:rtype: dict[str, int]
"""
# add layer to hyper params
if len(self.hidden_size) < self.max_hidden_layers: # HARD LIMIT
self.hidden_size += [self.hidden_size[-1]]
else:
return self.add_node()
return None
@mutation(MutationType.LAYER)
def remove_layer(self) -> dict[str, int] | None:
"""Remove a hidden layer from neural network. Falls back on ``add_node()`` if ``min_hidden_layers`` reached.
:return: Dictionary containing the hidden layer and number of new nodes.
:rtype: dict[str, int]
"""
if len(self.hidden_size) > self.min_hidden_layers: # HARD LIMIT
self.hidden_size = self.hidden_size[:-1]
else:
return self.add_node()
return None
@mutation(MutationType.NODE)
def add_node(
self,
hidden_layer: int | None = None,
numb_new_nodes: int | None = None,
) -> dict[str, int]:
"""Add nodes to hidden layer of neural network.
:param hidden_layer: Depth of hidden layer to add nodes to, defaults to None
:type hidden_layer: int, optional
:param numb_new_nodes: Number of nodes to add to hidden layer, defaults to None
:type numb_new_nodes: int, optional
:return: Dictionary containing the hidden layer and number of new nodes.
:rtype: dict[str, int]
"""
if hidden_layer is None:
hidden_layer = self.rng.integers(0, len(self.hidden_size))
else:
hidden_layer = min(hidden_layer, len(self.hidden_size) - 1)
if numb_new_nodes is None:
numb_new_nodes = int(self.rng.choice([16, 32, 64]))
# HARD LIMIT
if self.hidden_size[hidden_layer] + numb_new_nodes <= self.max_mlp_nodes:
self.hidden_size[hidden_layer] += numb_new_nodes
return {"hidden_layer": hidden_layer, "numb_new_nodes": numb_new_nodes}
@mutation(MutationType.NODE)
def remove_node(
self,
hidden_layer: int | None = None,
numb_new_nodes: int | None = None,
) -> dict[str, int]:
"""Remove nodes from hidden layer of neural network.
:param hidden_layer: Depth of hidden layer to remove nodes from, defaults to None
:type hidden_layer: int, optional
:param numb_new_nodes: Number of nodes to remove from hidden layer, defaults to None
:type numb_new_nodes: int, optional
:return: Dictionary containing the hidden layer and number of new nodes.
:rtype: dict[str, int]
"""
if hidden_layer is None:
hidden_layer = self.rng.integers(0, len(self.hidden_size))
else:
hidden_layer = min(hidden_layer, len(self.hidden_size) - 1)
if numb_new_nodes is None:
numb_new_nodes = int(self.rng.choice([16, 32, 64]))
# HARD LIMIT
if self.hidden_size[hidden_layer] - numb_new_nodes > self.min_mlp_nodes:
self.hidden_size[hidden_layer] -= numb_new_nodes
return {"hidden_layer": hidden_layer, "numb_new_nodes": numb_new_nodes}
def recreate_network(self) -> None:
"""Recreates the neural network while preserving the parameters of the old network."""
model = create_mlp(
input_size=self.num_inputs,
output_size=self.num_outputs,
hidden_size=self.hidden_size,
output_vanish=self.output_vanish,
output_activation=self.output_activation,
noisy=self.noisy,
init_layers=self.init_layers,
layer_norm=self.layer_norm,
output_layernorm=self.output_layernorm,
activation=self.activation,
noise_std=self.noise_std,
new_gelu=self.new_gelu,
device=self.device,
name=self.name,
)
self.model = EvolvableModule.preserve_parameters(
old_net=self.model,
new_net=model,
)
Tutorial
- Integrating Architecture Mutations Into SimBa
Build and evolve a Simba-style architecture.
- Building a Dueling Distributional Q Network
Custom Rainbow DQN network design
Policies, Value Functions, and More Complex Networks¶
In Reinforcement Learning, we often require processing very different types of observations into either actions or values / state-action values.
In order to make the implementation of evolvable policies, value functions, and more complex networks as seamless as possible, we define the EvolvableNetwork
base class which inherits from EvolvableModule. The diagram below shows the expected structure of a neural network inheriting from this class.
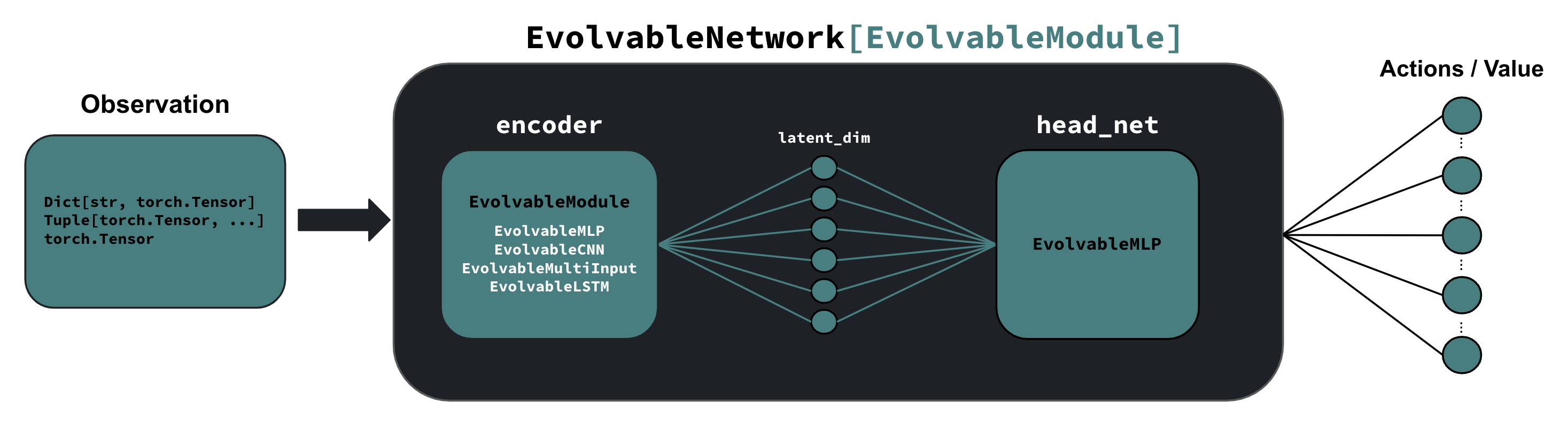
Structure of an EvolvableNetwork, showing the underlying encoder and head networks which are EvolvableModule objects themselves.¶
This abstraction allows us to define common networks used in RL algorithms very simply, since it automatically creates an appropriate encoder for the passed observation space. After,
we just create a head to the the network that processes the encoded observations into an appropriate number of outputs (for e.g. policies or critics). Off-the-shelf EvolvableNetwork’s
in AgileRL natively support the following observation spaces:
Box: Use anEvolvableMLP,EvolvableCNN, orEvolvableLSTMas the encoder, depending on the dimensionality of the observation space.
Dict/Tuple: Use anEvolvableMultiInputas the encoder.
MultiBinary/MultiDiscrete: Use anEvolvableMLPas the encoder.
The encoder processes observations into a latent space, which is then processed by the head network (usually a EvolvableMLP) to form the final output of the network. The
following networks, common in a variety of reinforcement learning algorithms, are available in AgileRL:
QNetwork: Outputs a state-action value given an observation and action (used in e.g. DQN).
RainbowQNetwork: Uses a distributional dueling architecture to output a distribution of state-action values given an observation and action (used in e.g. Rainbow DQN).
ContinuousQNetwork: Outputs a continuous state-action value given an observation and action (used in e.g. DDPG, TD3).
ValueNetwork: Outputs a single value given an observation (used in e.g. PPO, bandit algorithms).
DeterministicActor: Outputs deterministic actions given an observation (used in e.g. DDPG, TD3).
StochasticActor: Outputs stochastic actions given an observation (used in e.g. PPO).
Note
All EvolvableNetwork objects expect that the only modules that contribute towards its mutation method are the encoder and head networks. This is
done to ensure that the same mutation can be applied across the different networks optimized in an algorithm during training e.g. actor and critic, since
these usually solve problems that are very similar in nature and thus require similar architectures.
Configuring the Architecture of an EvolvableNetwork¶
In order to configure the architecture of EvolvableNetwork’s, we must pass in separate dictionaries that specify the architecture of the encoder and head networks through
the encoder_config and head_config arguments of the constructor of the EvolvableNetwork class. These dictionaries should include the initialisation arguments of the
corresponding EvolvableModule.
If your environment has a 1D Box observation space, by default the EvolvableNetwork will use a EvolvableMLP as the encoder.
Example MLP Network Configuration
from gymnasium.spaces import Box, Discrete
from agilerl.networks.q_networks import QNetwork
encoder_config = {
"hidden_size": [64, 64] # Two layers of 64 nodes each
"min_mlp_nodes": 16 # minimum number of nodes in the MLP when mutating
"max_mlp_nodes": 128 # maximum number of nodes in the MLP when mutating
}
head_config = {
"hidden_size": [64, 64] # Two layers of 64 nodes each
"min_mlp_nodes": 16, # minimum number of nodes in the MLP when mutating
"max_mlp_nodes": 128, # maximum number of nodes in the MLP when mutating
}
observation_space = Box(low=-100, high=100, shape=(10,))
action_space = Discrete(2)
network = QNetwork(
observation_space,
action_space,
encoder_config=encoder_config,
head_config=head_config,
latent_dim=32, # Dimension of the latent space representation
min_latent_dim=8, # Minimum dimension of the latent space representation
max_latent_dim=128, # Maximum dimension of the latent space representation
)
If your environment has a 3D Box observation space, by default the EvolvableNetwork will use a EvolvableCNN as the encoder.
Example CNN Network Configuration
from gymnasium.spaces import Box, Discrete
from agilerl.networks.actors import StochasticActor
encoder_config = {
"channel_size": [32, 64, 128], # Three convolutional layers with 32, 64, and 128 channels respectively
"kernel_size": [8, 4, 3], # The kernel sizes of the convolutional layers
"stride_size": [4, 2, 1], # The stride sizes of the convolutional layers
"min_channel_size": 16, # minimum number of channels in the CNN when mutating
"max_channel_size": 256, # maximum number of channels in the CNN when mutating
}
head_config = {
"hidden_size": [64, 64] # Two layers of 64 nodes each
"min_mlp_nodes": 16, # minimum number of nodes in the MLP when mutating
"max_mlp_nodes": 128, # maximum number of nodes in the MLP when mutating
}
observation_space = Box(low=-100, high=100, shape=(10, 10, 10))
action_space = Discrete(2)
network = StochasticActor(
observation_space,
action_space,
encoder_config=encoder_config,
head_config=head_config,
latent_dim=32, # Dimension of the latent space representation
min_latent_dim=8, # Minimum dimension of the latent space representation
max_latent_dim=128, # Maximum dimension of the latent space representation
)
If your environment has a dictionary or tuple observation space, by default the EvolvableNetwork will use an EvolvableMultiInput as the encoder.
Example Multi-Input Network Configuration
from gymnasium.spaces import Dict, Discrete, Box
from agilerl.networks.actors import StochasticActor
# Encoder configuration
encoder_config = {
"latent_dim": 32, # Latent dimension outputted by underlying feature extractors
"min_latent_dim": 8, # Minimum latent dimension when mutating
"max_latent_dim": 128, # Maximum latent dimension when mutating
"mlp_config": {
"hidden_size": [32, 32],
"activation": "ReLU",
},
"cnn_config": {
"channel_size": [32, 64, 64], # Three convolutional layers with 32, 64, and 64 channels respectively
"kernel_size": [8, 4, 3], # The kernel sizes of the convolutional layers
"stride_size": [4, 2, 1], # The stride sizes of the convolutional layers
"min_channel_size": 16, # minimum number of channels in the CNN when mutating
"max_channel_size": 256, # maximum number of channels in the CNN when mutating
"activation": "ReLU",
},
"lstm_config": None, # No LSTM required for this observation space
"vector_space_mlp": True # Process vector observations with an MLP
}
# MLP head configuration
head_config = {
"hidden_size": [64, 64] # Two layers of 64 nodes each
"min_mlp_nodes": 16, # minimum number of nodes in the MLP when mutating
"max_mlp_nodes": 128, # maximum number of nodes in the MLP when mutating
}
observation_space = Dict(
{
"vector": Box(low=-100, high=100, shape=(65,)),
"discrete": Discrete(111),
"image": Box(low=0, high=255, shape=(3, 84, 84)),
}
)
action_space = Discrete(2)
network = StochasticActor(
observation_space,
action_space,
encoder_config=encoder_config,
head_config=head_config,
latent_dim=32, # Dimension of the latent space representation
min_latent_dim=8, # Minimum dimension of the latent space representation
max_latent_dim=128, # Maximum dimension of the latent space representation
)
Note
In AgileRL algorithms, we pass a single net_config dictionary that includes the encoder_config and head_config dictionaries, as well as
any other initialisation arguments to the respective network used in the algorithm. This becomes more complex in multi-agent settings, where there are
multiple networks that can be configured.
See also
Configuring Network Architectures for details on configuring networks in multi-agent settings.
Using Non-Evolvable Networks in an Evolvable Setting¶
It might be the case that users require using either pre-trained networks or custom architectures that don’t inherit from EvolvableModule, but still wish
to exploit parameter optimization to automatically tune the RL hyperparameters of an algorithm. In order to do this, users can use DummyEvolvable
to wrap their non-evolvable networks in a manner compatible with our mutations framework - disabling architecture mutations but still allowing for RL hyperparameter and random weight mutations.
Example
import torch
import torch.nn as nn
from sgilerl.algorithms import DQN
from agilerl.modules.dummy import DummyEvolvable
class BasicNetActorDQN(nn.Module):
def __init__(self, input_size, hidden_sizes, output_size):
super().__init__()
layers = []
# Add input layer
layers.append(nn.Linear(input_size, hidden_sizes[0]))
layers.append(nn.ReLU()) # Activation function
# Add hidden layers
for i in range(len(hidden_sizes) - 1):
layers.append(nn.Linear(hidden_sizes[i], hidden_sizes[i + 1]))
layers.append(nn.ReLU()) # Activation function
# Add output layer with a sigmoid activation
layers.append(nn.Linear(hidden_sizes[-1], output_size))
# Combine all layers into a sequential model
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
actor_kwargs = {
"input_size": 4, # Input size
"hidden_sizes": [64, 64], # Hidden layer sizes
"output_size": 2 # Output size
}
actor = DummyEvolvable(
device=device,
module_fn=BasicNetActorDQN,
module_kwargs=actor_kwargs,
)
# Use the actor in an algorithm
observation_space = ...
action_space = ...
population = DQN.population(
size=4,
observation_space=observation_space,
action_space=action_space
actor_network=actor
)
Integrating Architecture Mutations Into a Custom PyTorch Network¶
Deprecated since version 2.0.0: The following section pertains to the MakeEvolvable wrapper, which will be removed in a
future release. We recommend using the EvolvableModule and EvolvableNetwork
classes to create custom networks, or wrapping your nn.Module objects with DummyEvolvable.
For sequential architectures that users have already implemented using PyTorch, it is also possible to add
evolvable functionality through the MakeEvolvable wrapper. Below is an example of a simple multi-layer
perceptron that can be used by a DQN agent to solve the Lunar Lander environment. The input size is set as the state dimensions and output size the action dimensions.
It’s worth noting that, during the model definition, it is imperative to employ the torch.nn module to define all layers instead of relying on functions from
torch.nn.functional within the forward() method of the network. This is crucial as the forward hooks implemented will only be able to detect layers derived from nn.Module.
Example PyTorch Network
import torch.nn as nn
import torch
class MLPActor(nn.Module):
def __init__(self, input_size, output_size):
super(MLPActor, self).__init__()
self.linear_layer_1 = nn.Linear(input_size, 64)
self.linear_layer_2 = nn.Linear(64, output_size)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.linear_layer_1(x))
x = self.linear_layer_2(x)
return x
To make this network evolvable, simply instantiate an MLPActor object and then pass it, along with an input tensor into
the MakeEvolvable wrapper.
Making it Evolvable
from agilerl.wrappers.make_evolvable import MakeEvolvable
observation_space = env.single_observation_space
action_space = env.single_action_space
actor = MLPActor(observation_space.shape[0], action_space.n)
evolvable_actor = MakeEvolvable(
actor,
input_tensor=torch.randn(observation_space.shape[0]),
device=device
)
When instantiating using Algorithm.population() to generate a population of agents with a custom actor,
pass the actor_network keyword argument.
Using it in a Population
from agilerl.algorithms import DQN
# Algorithm hyperparameters
init_hp = {
"batch_size": 128,
"lr": 1e-3,
"gamma": 0.99,
}
# Initialize population
population_size = 4
pop = DQN.population(
size=population_size,
observation_space=observation_space,
action_space=action_space,
actor_network=evolvable_actor,
device=device,
**init_hp,
)
If you are using an algorithm that also uses a single critic (PPO, DDPG), define the critic network and pass it as
critic_network.
Using it in a Population with a Single Critic
from agilerl.algorithms import PPO
# Algorithm hyperparameters
init_hp = {
"batch_size": 128,
"lr": 1e-3,
"gamma": 0.99,
}
# Initialize population
pop = PPO.population(
size=4,
observation_space=observation_space,
action_space=action_space,
actor_network=evolvable_actor,
critic_network=evolvable_critic,
device=device,
**init_hp,
)
If the single agent algorithm has more than one critic (e.g. TD3), then pass a list of two critics as critic_network.
Using it in a Population with Multiple Critics
from agilerl.algorithms import TD3
# Algorithm hyperparameters
init_hp = {
"batch_size": 128,
"lr_actor": 1e-3,
"lr_critic": 1e-3,
"gamma": 0.99,
}
# Initialize population
pop = TD3.population(
size=4,
observation_space=observation_space,
action_space=action_space,
actor_network=evolvable_actor,
critic_network=[evolvable_critic_1, evolvable_critic_2],
device=device,
**init_hp,
)
If you are using a multi-agent algorithm, define actor_network and critic_network as lists containing networks for each agent in the
multi-agent environment. The example below outlines how this would work for a two agent environment (asumming you have initialised a multi-agent
environment in the variable env).
Example
from agilerl.algorithms import MADDPG
# For MADDPG
evolvable_actors = [actor_network_1, actor_network_2]
evolvable_critics = [critic_network_1, critic_network_2]
# For MATD3, "critics" will be a list of 2 lists as MATD3 uses one more critic than MADDPG
evolvable_actors = [actor_network_1, actor_network_2]
evolvable_critics = [[critic_1_network_1, critic_1_network_2],
[critic_2_network_1, critic_2_network_2]]
# Instantiate the populations as follows
observation_spaces = [env.single_observation_space(agent) for agent in env.agents]
action_spaces = [env.single_action_space(agent) for agent in env.agents]
# Algorithm hyperparameters
init_hp = {
"batch_size": 128,
"lr_actor": 1e-3,
"lr_critic": 1e-3,
"gamma": 0.99,
}
# Initialize population
pop = MADDPG.population(
size=4,
observation_space=observation_spaces,
action_space=action_spaces,
actor_network=evolvable_actors,
critic_network=evolvable_critics,
device=device,
**init_hp,
)
Finally, if you are using a multi-agent algorithm but need to use CNNs to account for RGB image states, there are a few extra considerations
that need to be taken into account when defining your critic network. In MADDPG and MATD3, each agent consists of an actor and critic and each
critic evaluates the states and actions of all agents that act in the multi-agent system. Unlike with non-RGB environments that require MLPs, we cannot
immediately stack the state and action tensors due to differing dimensions, we must first pass the state tensor through the convolutinal layers,
before flattening the output, combining with the actions tensor, and then passing this combined state-action tensor into the fully-connected layer.
This means that when defining the critic, the .forward() method must account for two input tensors (states and actions). Below are examples of
how to define actor and critic networks for a two agent system with state tensors of shape (4, 210, 160):
Example CNN Networks
from agilerl.networks.custom_activation import GumbelSoftmax
class MultiAgentCNNActor(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv3d(
in_channels=4, out_channels=16, kernel_size=(1, 3, 3), stride=4
)
self.conv2 = nn.Conv3d(
in_channels=16, out_channels=32, kernel_size=(1, 3, 3), stride=2
)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(15200, 256)
self.fc2 = nn.Linear(256, 2)
self.relu = nn.ReLU()
self.output_activation = GumbelSoftmax()
def forward(self, state_tensor):
x = self.relu(self.conv1(state_tensor))
x = self.relu(self.conv2(x))
x = x.view(x.size(0), -1)
x = self.relu(self.fc1(x))
x = self.output_activation(self.fc2(x))
return x
class MultiAgentCNNCritic(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv3d(
in_channels=4, out_channels=16, kernel_size=(2, 3, 3), stride=4
)
self.conv2 = nn.Conv3d(
in_channels=16, out_channels=32, kernel_size=(1, 3, 3), stride=2
)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(15208, 256)
self.fc2 = nn.Linear(256, 2)
self.relu = nn.ReLU()
def forward(self, state_tensor, action_tensor):
x = self.relu(self.conv1(state_tensor))
x = self.relu(self.conv2(x))
x = x.view(x.size(0), -1)
x = torch.cat([x, action_tensor], dim=1)
x = self.relu(self.fc1(x))
x = self.fc2(x)
return x
To then make these two CNNs evolvable we pass them, along with input tensors into the MakeEvolvable wrapper.
Example
actor = MultiAgentCNNActor()
evolvable_actor = MakeEvolvable(
network=actor,
input_tensor=torch.randn(1, 4, 1, 210, 160),
device=device,
)
critic = MultiAgentCNNCritic()
evolvable_critic = MakeEvolvable(
network=critic,
input_tensor=torch.randn(1, 4, 2, 210, 160),
secondary_input_tensor=torch.randn(1, 8),
device=device,
)
Compatible Architecture¶
At present, MakeEvolvable is currently compatible with PyTorch multi-layer perceptrons (MLPs) and convolutional neural networks (CNNs). The
network architecture must also be sequential, that is, the output of one layer serves as the input to the next layer. Outlined below is a comprehensive
table of PyTorch layers that are currently supported by this wrapper:
Layer Type |
PyTorch Compatibility |
|---|---|
Pooling |
|
Activation |
|
Normalization |
|
Convolutional |
|
Linear |
|
Compatible Algorithms¶
The following table highlights which AgileRL algorithms are currently compatible with custom architecture:
CQL |
DQN |
DDPG |
TD3 |
PPO |
MADDPG |
MATD3 |
ILQL |
Rainbow-DQN |
|---|---|---|---|---|---|---|---|---|
✔️ |
✔️ |
✔️ |
✔️ |
✔️ |
✔️ |
✔️ |
❌ |
✔️ |